
About Me
I am a researcher in industry. I recently completed my PhD in theoretical physics at Harvard, where I was very fortunate to be advised by Cengiz Pehlevan. My research is on developing a science of deep learning to inform the design of AI systems that are more performant, reliable, and interpretable. I approach this by leveraging statistical physics, random matrix theory, and extensive empirical studies on real models and datasets. Key ideas include the neural tangent kernel, maximal update parameterization (μP), and the dichotomy between rich and lazy training. An important application of these ideas is to the study of neural scaling laws. See this note for a 2-page derivation of key scaling laws obtained in my PhD. My work was funded by the NDSEG Fellowship (2019-2022) and by the Hertz Fellowship (2019-2024).
Prior to this, I had the pleasure of collaborating with Andy Strominger and colleagues on topics adjacent to string theory and quantum field theory. Also while in graduate school, I consulted for two biotech firms: Protein Evolution and Quantum Si as a machine learning scientist. I've also worked at Jane Street as a quantiative research intern, at Google applying deep learning to computer vision, and at the Perimeter Institute under Erik Schnetter on tackling the curse of dimensionality in numerical partial differential equations.
I received my M.S. in mathematics and B.S. in physics from Yale in 2018. There, I studied conformal field theories under David Poland, using the bootstrap program. I also studied computational neuroscience in John Murray's lab, where we built tools to study working memory in recurrent neural networks. My master's thesis in pure math was under Philsang Yoo on connections of quantum field theory to the Langlands program.
My earliest exposure to scientific research was under Dr. James Ellenbogen at MITRE, and with Drs. John Dell and Jonathan Osborne at Thomas Jefferson High School.
Publications
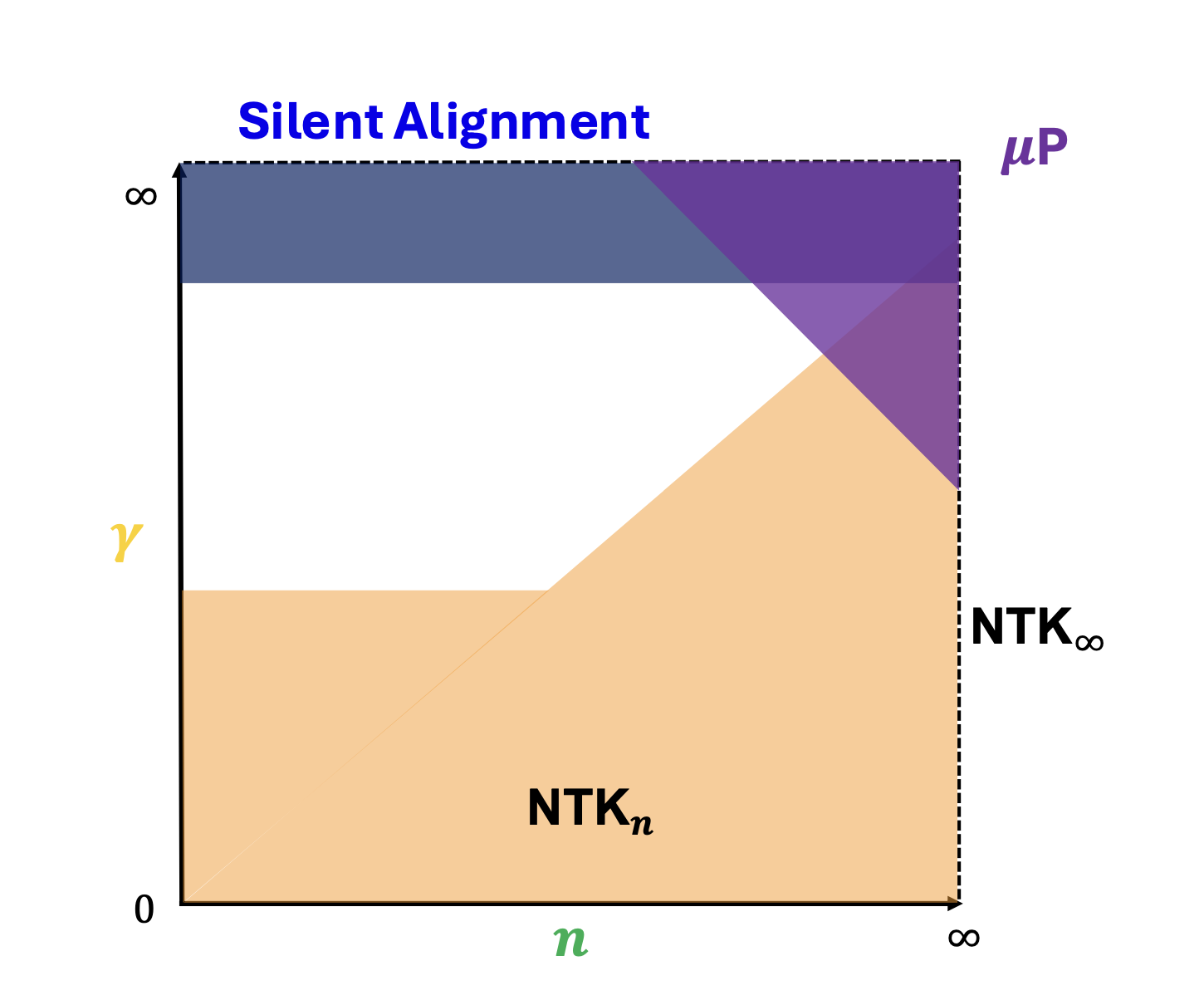
PhD Thesis: Scaling and Renormalization in Statistical Learning
Abstract: This thesis develops a theoretical framework for understanding the scaling properties of information processing systems in the regime of large data, large model size, and large computational resources. The goal is to develop an understanding of the impressive performance that deep neural networks have exhibited.
The first part of this thesis examines models linear in their parameters but nonlinear in their inputs. This includes linear regression, kernel regression, and random feature models. Utilizing random matrix theory and free probability, I provide precise characterizations of their training dynamics, generalization capabilities, and out-of-distribution performance, alongside a detailed analysis of sources of variance. A variety of scaling laws observed in state-of-the-art large language and vision models are already present in this simple setting.
The second part of this thesis focuses on representation learning. Leveraging insights from models linear in inputs but nonlinear in parameters, I present a theory of early-stage representation learning where a network with small weight initialization can learn features without altering the loss. This phenomenon, termed silent alignment, is empirically validated across various architectures and datasets. The idea of starting at small initialization leads naturally to the "maximal update parameterization", μP, that allows for feature learning at infinite width. I present empirical studies showing that practical networks can approach their theoretical infinite-width feature learning limits. Finally, I consider down-scaling the output of a neural network by a fixed constant. When this constant is small, the network behaves as a linear model in parameters; when large, it induces silent alignment. I present theoretical and empirical results of the influence of this hyperparameter on feature learning, performance, and dynamics.
Committee: Cengiz Pehlevan, Haim Sompolinsky, and Michael Brenner.(2024) Accepted [Harvard] [ProQuest]
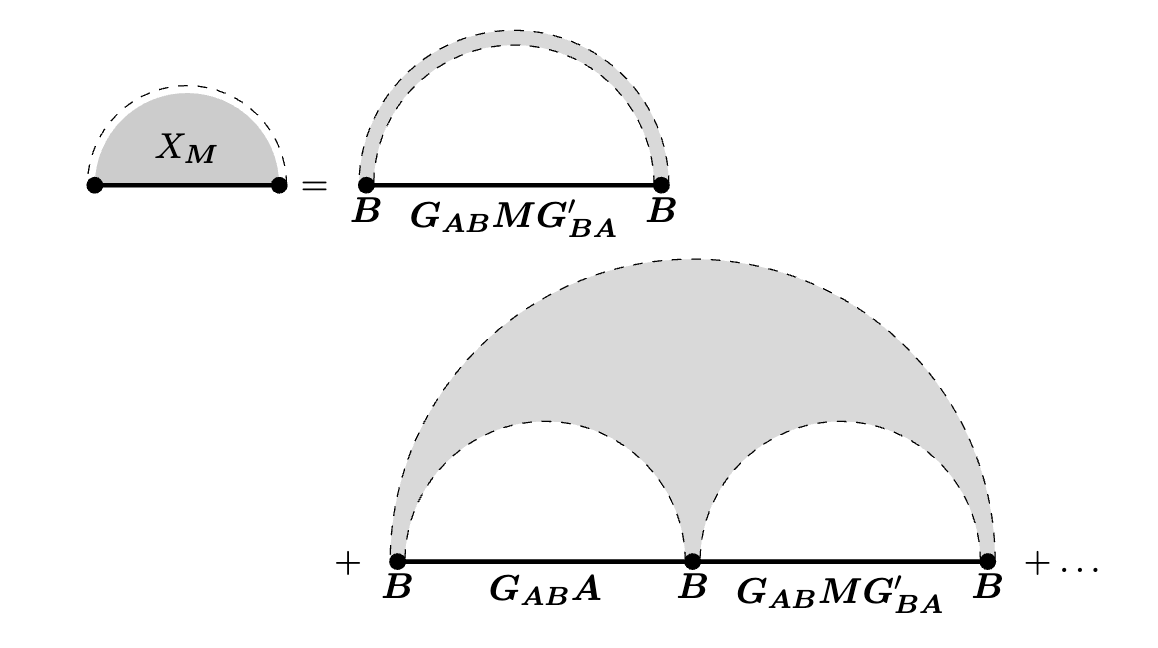
Two-Point Deterministic Equivalence for Stochastic Gradient Dynamics in Linear Models
Work with Blake Bordelon, Jacob Zavatone-Veth, Courtney Paquette and Cengiz Pehlevan. Using random matrix theory, we derive a novel deterministic equivalence. Essentially all results (up to that point) on models of neural scaling laws in high-dimensional regression follow directly from this equivalence. This accounts for finite training time, finite dataset size, finite parameter count, and SGD effects jointly.(2025) ICML 2025 Workshop on High-dimensional Learning Dynamics [OpenReview] [arXiv]
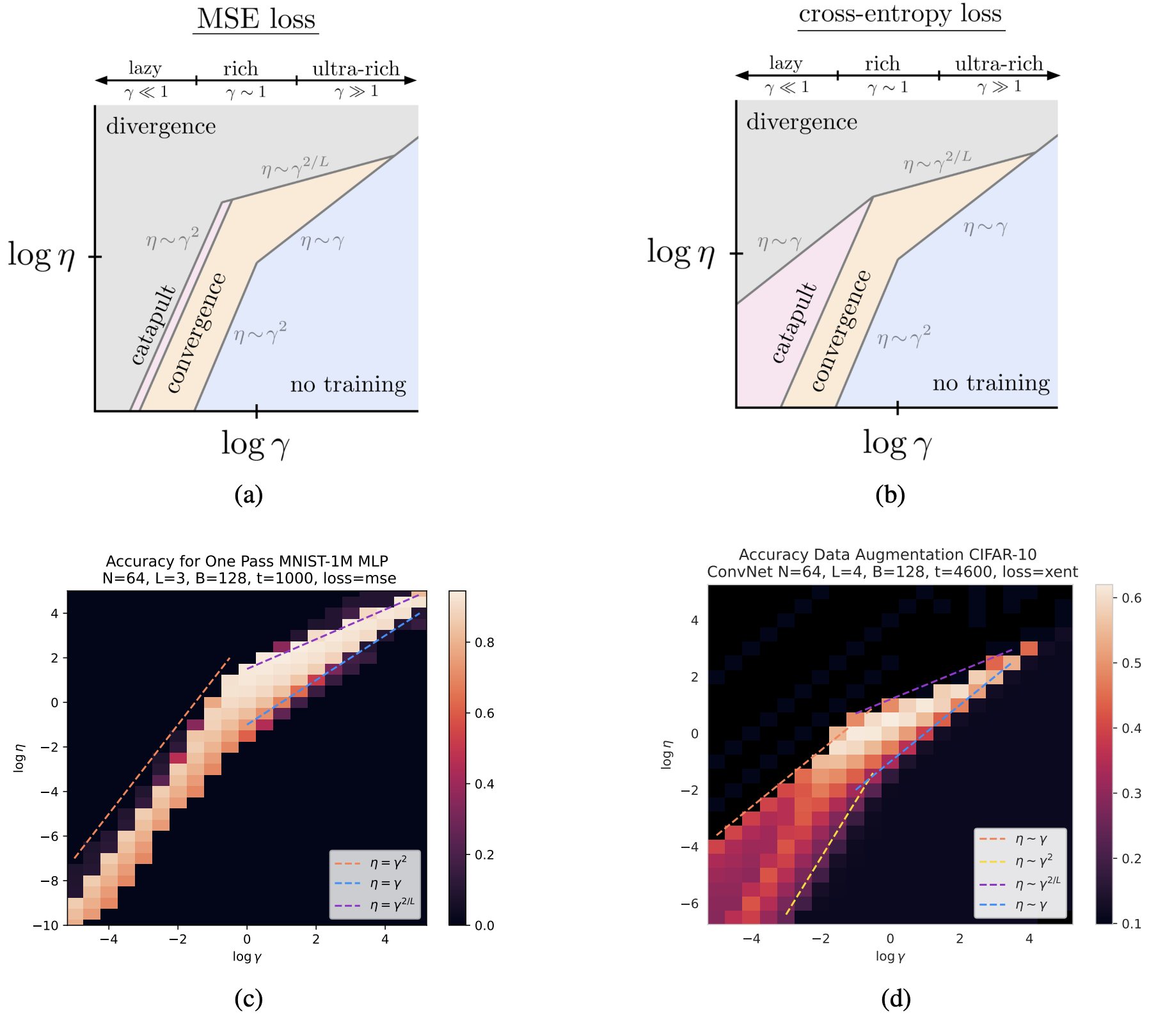
The Optimization Landscape of SGD Across the Feature Learning Strength
Work with Jamie Simon, Alex Meterez, and Cengiz Pehlevan. We perform a thorough sweep over the feature learning strength (also known as the "richness") for large-scale networks trained on real data. We find that the optimal learning rate in SGD depends nontrivially on the richness, in a way that has not been explored in prior literature. We focus on the online setting, representative of modern large models. This setting has been underexplored both theoretically and empirically when studying the effect of richness. We identify several scaling regimes of the learning rate with the richness, and explain them in a simple model. These regimes exhibit a wealth of different dynamical phenomena, including catapult effects, progressive sharpening, and the silent alignment effect. After accounting for the learning rate, we find that richer networks are at least as good as standard networks. We also observe a remarkable consistency of dynamics, learned functions, and learned representations in the ultra-rich regime that has not been previously reported.(2024) ICLR 2025 [OpenReview] [arXiv]
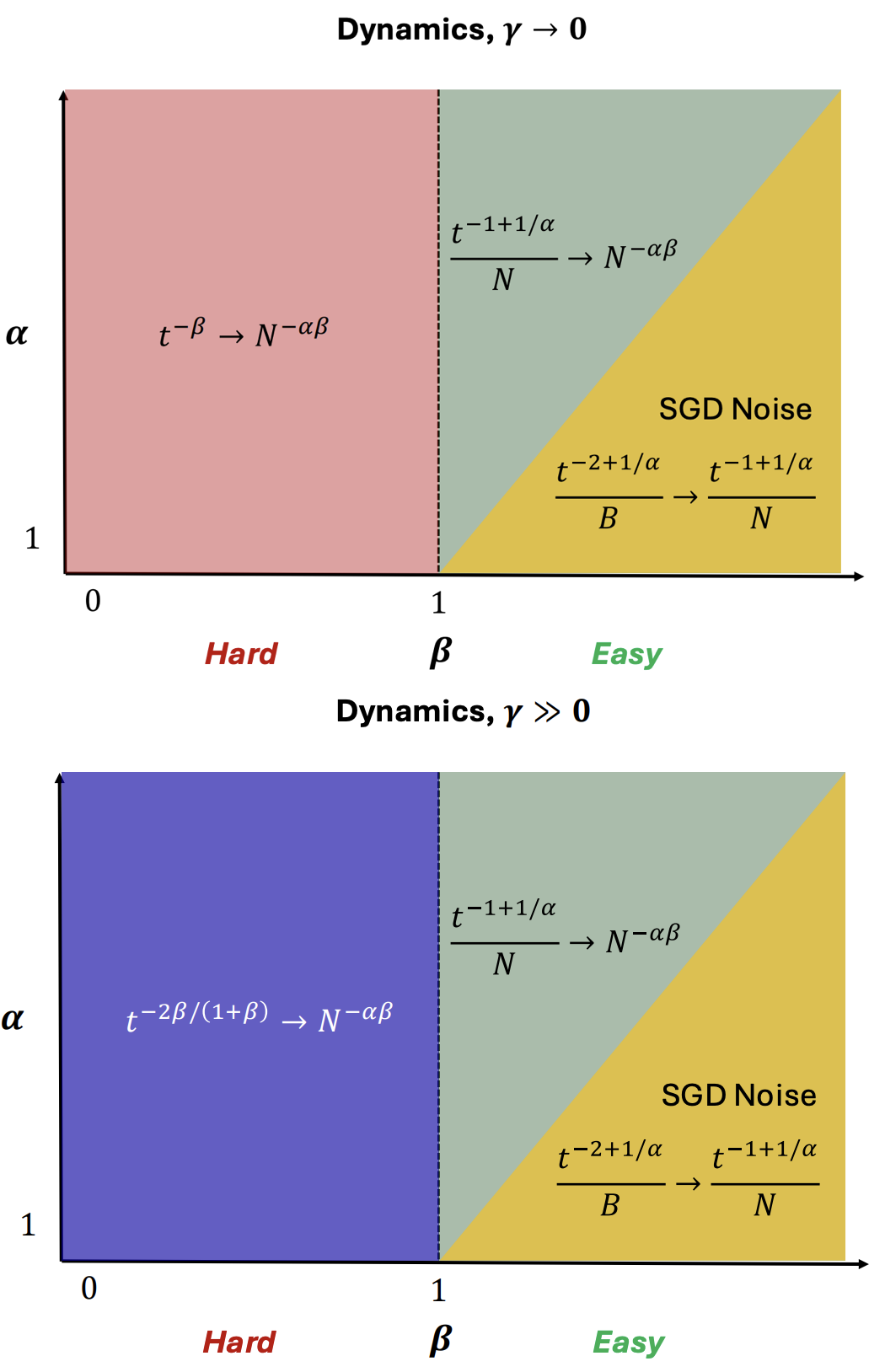
How Feature Learning Can Improve Neural Scaling Laws
Work with Blake Bordelon and Cengiz Pehlevan. We propose the simplest model where feature learning yields a concrete and measurable improvement to the neural scaling law of performance with time. By leveraging linear network theory combined with dynamical mean field theory, we derive exact analytic expressions for the dynamics. We identify three scaling regimes corresponding to varying task difficulties: hard, easy, and super easy tasks. For easy and super-easy target functions, which lie in the reproducing kernel Hilbert space (RKHS) defined by the initial infinite-width Neural Tangent Kernel (NTK), the scaling exponents remain unchanged between feature learning and kernel regime models. For hard tasks, defined as those outside the RKHS of the initial NTK, we demonstrate both analytically and empirically that feature learning can improve scaling with training time and compute, nearly doubling the exponent for hard tasks. This leads to a different compute-optimal strategy to scale parameters and training steps in the feature-learning regime. We propose a hypothesis that feature learning only improves the scaling law if the task is outside the Hilbert space of the infinite width NTK, and dub this the Source Hypothesis, as it requires the source exponent to be below a specific threshold for feature learning to yield scaling improvement. We further extract corrections due to finite model size, finite dataset size, and SGD noise.(2024) ICLR 2025 (Spotlight) [OpenReview] [arXiv]
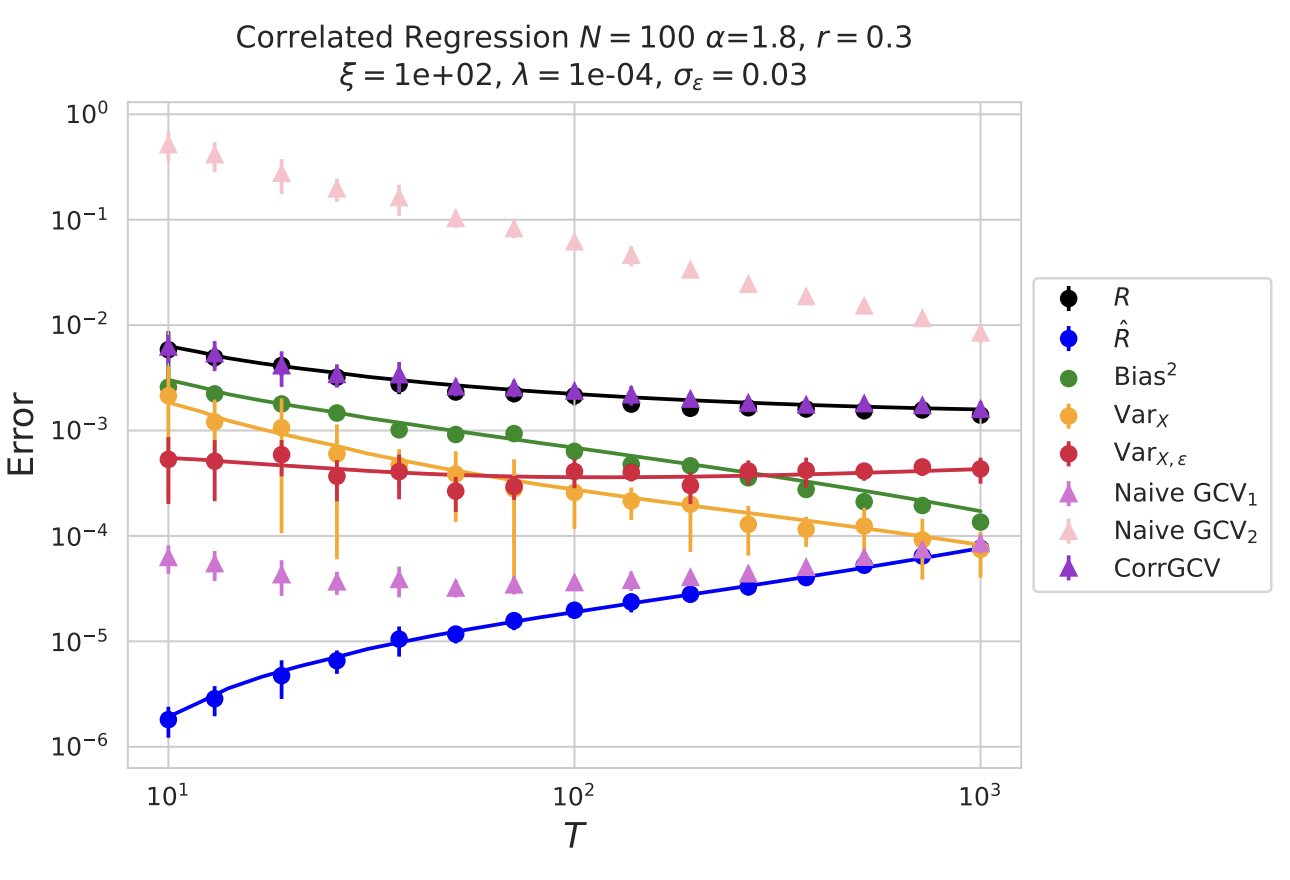
Risk and Cross Validation in Ridge Regression with Correlated Samples
Work with Jacob Zavatone-Veth and Cengiz Pehlevan. By leveraging techniques in modern random matrix theory and free probability, we obtain exact analytic results for the performance of ridge regression when samples have correlations between one another. This goes beyond the common i.i.d. setting that is usually studied. We demonstrate that in this setting, the generalized cross validation estimator (GCV) fails to correctly predict the out-of-sample risk. However, under realistic assumptions on the noise structure, we show that there exists a modification of the GCV that yields an efficiently-computable unbiased estimator of the out-of-sample risk. We dub this the CorrGCV. Finally, we also exactly characterize the over-optimism of testing on a point with nontrivial correlations to the training set.(2024) ICML 2025 [OpenReview] [arXiv]
Scaling and Renormalization in High-Dimensional Regression
Work with Jacob Zavatone-Veth and Cengiz Pehlevan. We introduce the basic concepts of random matrix theory and free probability necessary to characterize the performance of high-dimensional regression across a variety of machine learning models. By applying the S-transform of free probability, we provide a straightforward derivation of the average case behavior of many of the quantities of interest in these settings. We also provide novel formulas for the generalization error of general random feature models and fine-grained bias-variance decompositions in that setting. We go on to study the scaling properties of random feature models, and the effects of weight structure and additive feature noise. Our results extend and provide a unifying perspective on earlier models of neural scaling laws.(2024) In Submission [arXiv]
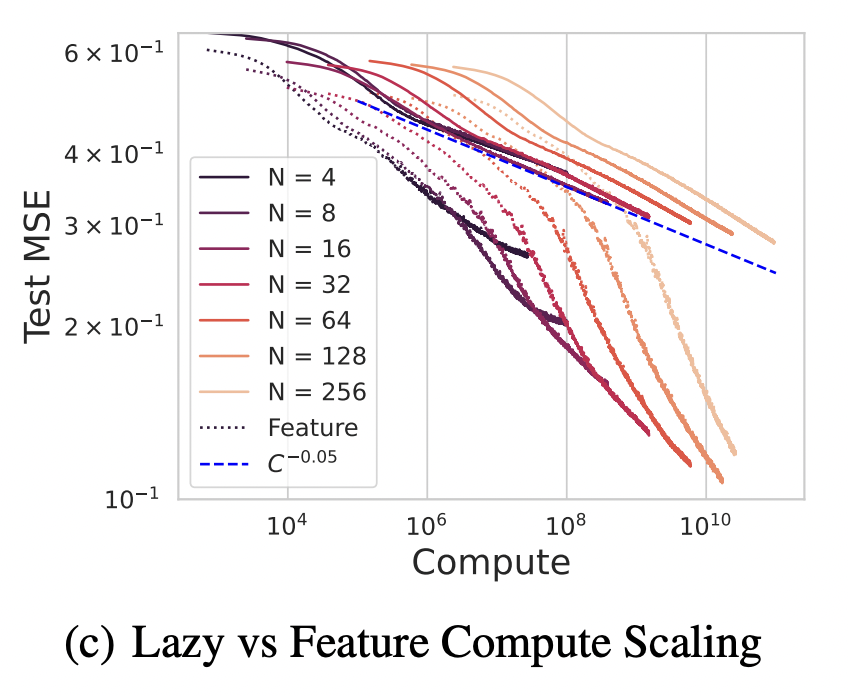
A Dynamical Model of Neural Scaling Laws
Work with Blake Bordelon and Cengiz Pehlevan. We study a model similar to our onset of variance paper, which involves projecting a large set of features down to a lower dimensional space and trying to reconstruct the signal from that. Here, however, we use dynamical mean field theory (DMFT) to analytically recover exact analytic expressions for the training and generalization dynamics of this model through time. This recovers many of the major phenomena observed in the training of large-scale language and vision models.(2024) ICML 2024 [OpenReview] [arXiv]
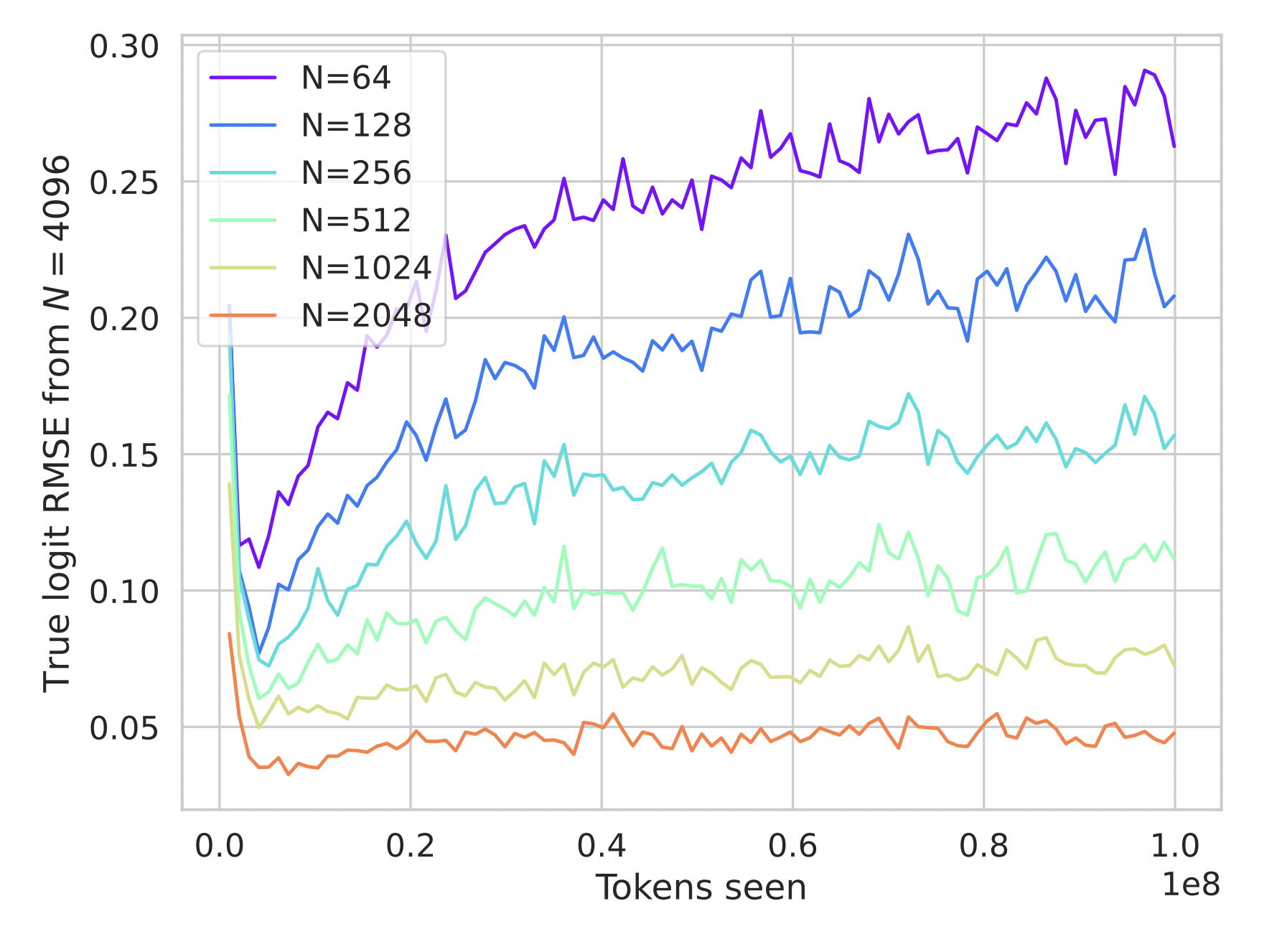
Maximal Update (μP) Networks Are Consistent Across Widths At Realistic Scales
Work with Nikhil Vyas, Blake Bordelon, Depen Morwani, Sabarish Sainathan, and Cengiz Pehlevan. We perform an extensive empirical study on realistic networks in the "maximal update parameterization" (μP) of Greg Yang (introduced by other authors under the name "mean field parameterization)". In this parameterization, networks can learn features even at infinite width. We study networks across realistic datasets for vision nets on (CIFAR-5m, ImageNet) and transformer models on (Wikitext-103, C4). Wider networks are seen to perform better, consistent with prior works. We show that not only do loss curves of realistically wide networks converge to a limiting behavior corresponding to the infinite width limit, but that the individual network outputs, internal representations, and dynamical phenomena also behave nearly identically across large widths. We find that this is robust across architectures and datasets in the setting where each example is new, but that when frequently repeating examples, it can be broken. Finally, we develop a new spectral perspective on the bias that can make narrower width networks perform worse, even after ensembling.(2023) NeurIPS 2023 [OpenReview] [arXiv]
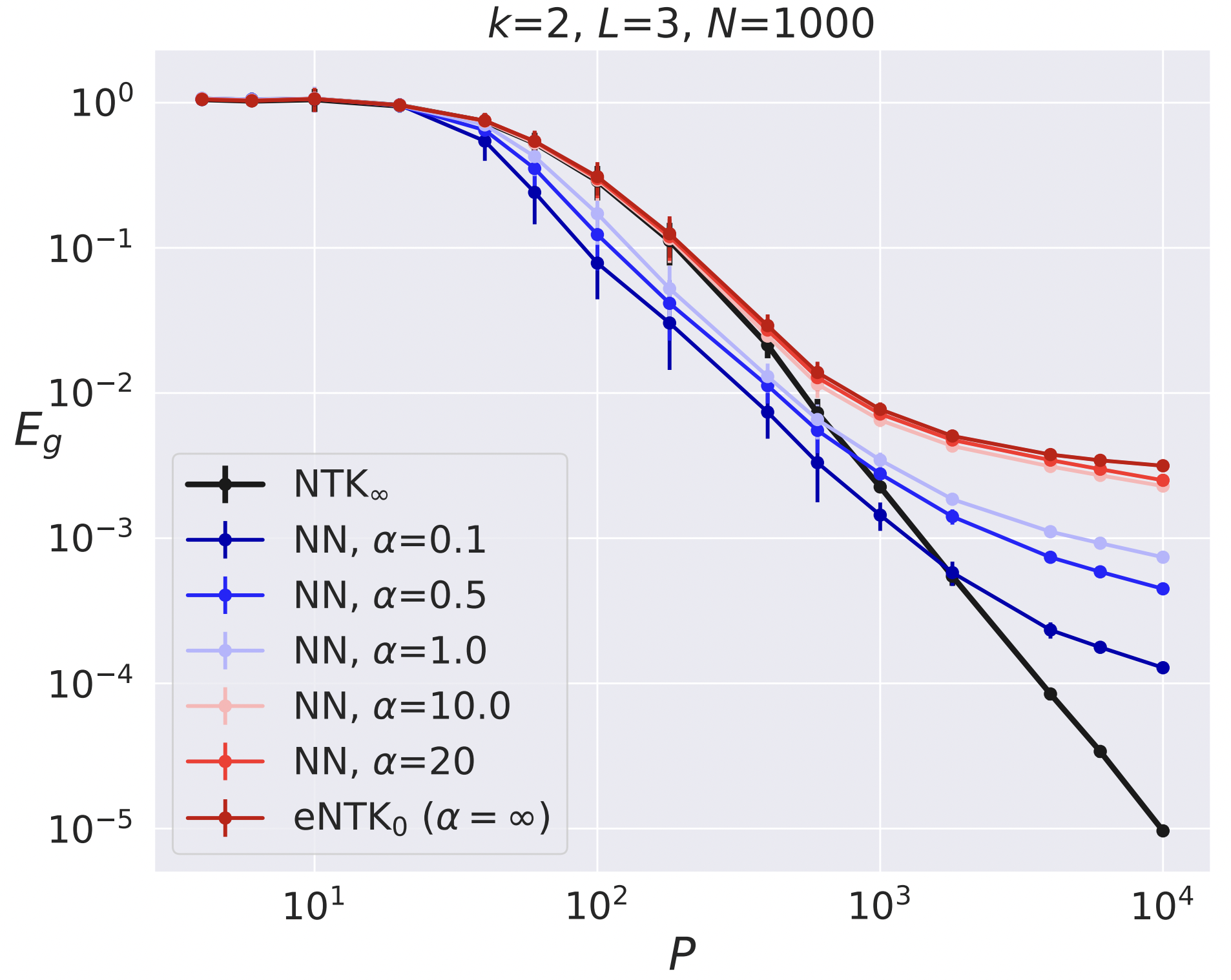
The Onset of Variance-Dominated Behavior for Networks in the Lazy and Rich Regimes
Work with Blake Bordelon, Sabarish Sainathan, and Cengiz Pehlevan. At infinite width, the training and generalization capabilities of neural networks simplify to those of kernel machines or "mean field limits". We empirically study the problem of polynomial interpolation with finite-width networks and observe that as the dataset size grows, the network enters a regime where it strictly underperforms its infinite-width counterpart. We demonstrate that this worse behavior is driven by initialization variance and that one can recover the infinite width limit to high accuracy by ensembling over sufficiently many initializations of the network. This transition can be delayed by feature learning. We demonstrate that this behavior is reproduced in a simple "signal plus noise" toy model.(2022) ICLR 2023 [OpenReview] [arXiv]
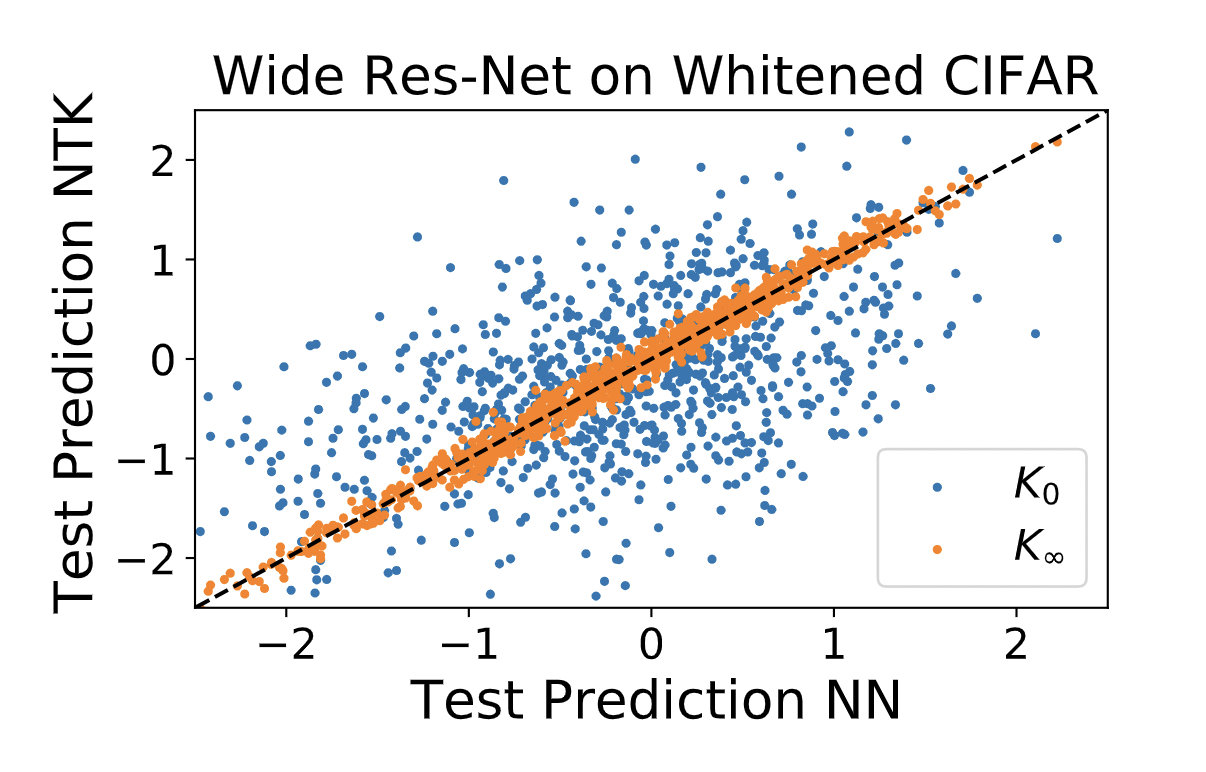
Neural Networks as Kernel Learners: The Silent Alignment Effect
Work with Blake Bordelon and Cengiz Pehlevan. In the limit of infinite hidden layer width, appropriately initialized neural networks become kernel machines with a data-independent neural tangent kernel (NTK). For finite width networks, the story changes, often drastically. This paper studies finite width networks at small initialization trained on whitened data and demonstrates how such networks can still be kernel machines with a data-dependent learned NTK. We analytically solve for the dynamics of linear networks in this regime and calculate the exact form of the final NTK. There, we identify a phase of training where the NTK aligns itself to the data well before it grows in absolute magnitude and before the loss drops substantially. We term this phenomenon "silent alignment". For nonlinear networks, much of the analysis goes through unchanged. We observe that in the case of unwhitened data, the network can realign itself drastically and not match the final NTK predictions.(2021) ICLR 2022 [OpenReview] [arXiv]
PsychRNN: An Accessible and Flexible Python Package for Training Recurrent Neural Network Models on Cognitive Tasks
A publication resulting from my undergraduate work in John Murray's lab. I worked on this from 2016-2018 in collaboration with David Brandfonbrener, Daniel Ehrlich, and Jasmine Stone. The goal of this package is to give a platform for computational neuroscience researchers to more easily construct neural network architectures with biological constraints. The focus is on RNN-type architectures relevant for the modeling of working memory.(2021) eNeuro [Journal Link] [bioRxiv] [Code Repository]
Precision Bootstrap for the N = 1 Super-Ising Model
Work with David Poland, Junchen Rong, Ning Su, and Aaron Hillman. We extend prior results from both of our groups on the minimal supersymmetric extension to the 3D Ising universality class to provide a more thorough numerical analysis. We combine this with analytic techniques coming from the structure of conformal theories at large spin and demonstrate solid agreement between analytic theory and numerical experiment. A deeper analytic understanding of this universality class may open the door for new methods and ideas to tackle its cousin: the 3D Ising model.(2022) Journal of High Energy Physics [Journal Link] [arXiv]
Conformal Block Expansion in Celestial Conformal Field Theory
Work with Andy Strominger and collaborators. Flat space amplitudes can be recast as correlation function on a ``celestial sphere'' at null infinity. These correlation functions are constrained to satisfy conformal covariance coming from the Lorentz group in flat spacetime. The corresponding 4-point correlation functions for a 2-to-2 scattering process can be expanded in terms of conformal blocks. This expansion captures the spectral data that is exchanged from the celestial perspective. For scalar external particles with massive scalar exchange, we find a new class of light-ray operators that are exchanged, and construct their corresponding waveforms in flat space.(2021) Physical Review D [Journal Link] [arXiv] [IAS Talk]
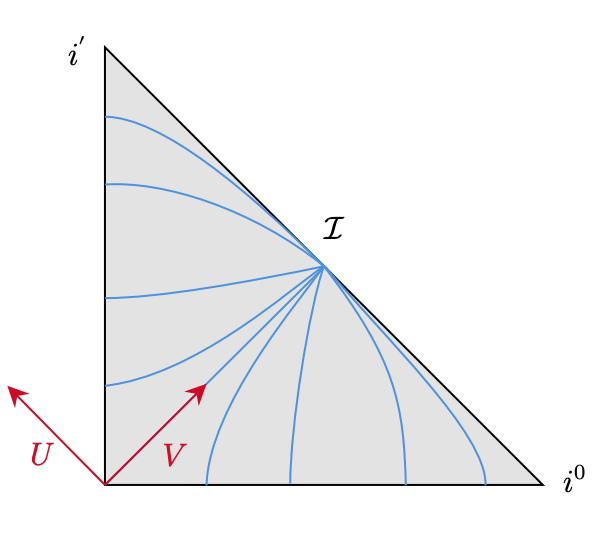
(2,2) Scattering and the Celestial Torus
Work with Andy Strominger and collaborators on understanding the asymptotic structure of spacetime in mixed 2,2 signature, which we call "Klein Space", and its relationship to scattering and the celestial holography program. We provide the resolution of null infinity in 2,2 signature as a torus fibration over an interval. The corresponding "celestial torus" is conjectured to hold a conformal field theory containing information on scattering processes. We derive a new basis of scattering states motivated by the symmetries of this torus, and relate this to the conventional Mellin basis used in the existing literature.(2021) Journal of High Energy Physics [Journal Link] [arXiv] [Princeton Talk]
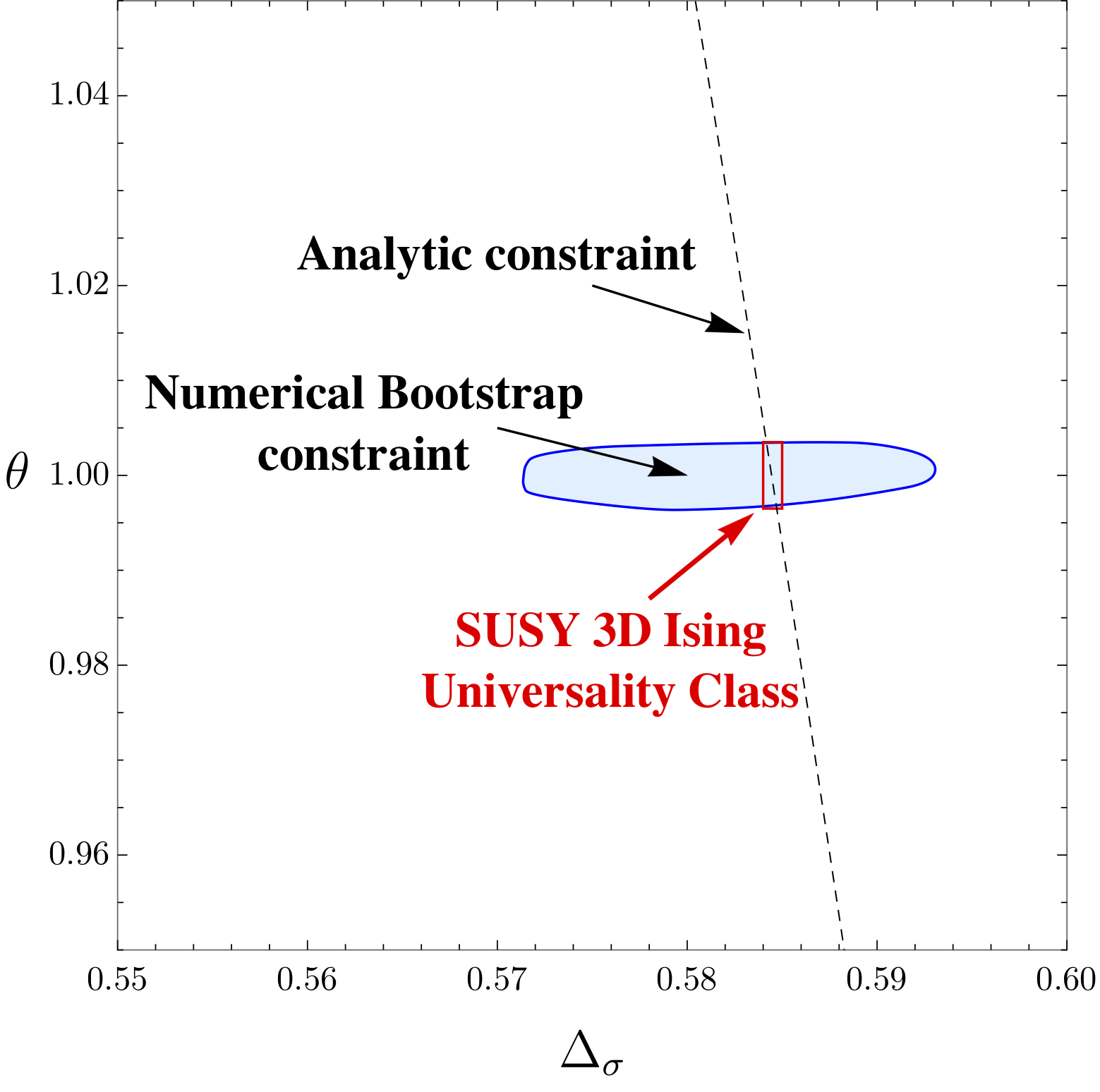
Bootstrapping the Minimal 3D Superconformal Field Theory
A paper written in collaboration with Aaron Hillman and my undergraduate physics advisor, Professor David Poland, published in the Journal of High Energy Physics (JHEP). We apply the conformal bootstrap program to study a space of interesting conformal field theories (CFTs). In the past, the conformal bootstrap has had great success in pinning down the critical exponents of the famously impenetrable 3D Ising model to the highest precision ever achieved. Here, we present a bootstrap study of the space of 3D CFTs sharing the same parity symmetry and relevant operator structure as the 3D Ising model. This space is diagrammed and elaborated upon in this beautifully-written Quanta article. We note a new kink that lies near the conjectured scaling dimensions of the 3D N = 1 Ising model: the Ising model's supersymmetric cousin. A noted prior work conjectures that this supersymmetric theory may in fact be emergent at the boundary of topological superconductors. By combining a scan over three-point function coefficients together with an analytic formula derived form supersymmetry that constrains the three-point correlators, we obtain tight bounds for the scaling dimensions and operator spectra of this model. Our results lead us to conjecture a surprising exact value for the 3-point coefficient ratio of this CFT. This then gives a conjectured exact analytic value for the scaling dimensions of the first two relevant scalars.(2018) Journal of High Energy Physics [Journal Link] [arXiv] [Code Repository]
Magnetic Monopoles, `t Hooft Lines, and the Geometric Langlands Correspondence
My undergraduate thesis in mathematics under my advisor, Professor Philsang Yoo. Provides an overview of the Geometric Langlands correspondence from the point of view of physics. This thesis is based on the material I learned from my advisor's two seminar courses on the subject, a variety of independent reading, and by attending a conference on the same topic at the Perimeter Institute.(2018) Yale Senior Thesis [PDF] [Presentation Slides]

Sparse Grid Discretizations based on a Discontinuous Galerkin Method
A paper written in collaboration with Dr. Erik Schnetter at the Perimeter Institute for theoretical physics, on using the discontinuous Galerkin method together with sparse grids to evolve scalar wave equations in higher dimensional spacetimes. We developed a julia package, GalerkinSparseGrids.jl for the implementation of this theory, and present its results for 5+1 and 6+1-dimensional wave evolutions in the paper. This yields a significant computational step forward in the capacity to solve hyperbolic partial differential equations in higher dimensional space, and we hope to extend this work to Einstein's equations in an anisotropic spacetime.(2017) [arXiv] [PDF] [Code Repository]
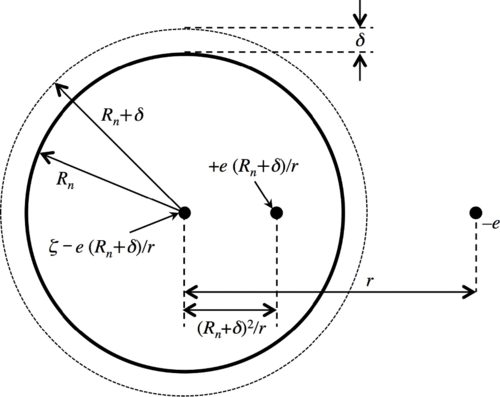
Simple, accurate electrostatics-based formulas for calculating detachment energies of fullerenes
A paper written in collaboration with Dr. James Ellenbogen at the MITRE Corporation, published in Physical Review A, on deriving a simple analytic formulas via electrostatics-based methods to accurately calculate the values of electron affinities, ionization potentials, and capacitances of icosahedral carbon fullerenes. The aforementioned analytic formulae yield significant insight into both the physics of electron detachment in the fullerenes and shed light on prior investigations of the relationship between sizes of the fullerenes and their molecular capacitances.(2017) Physical Review A [Journal Link] [PDF]
Graded Lie Algebras, Supersymmetry, and Applications
Final term paper on supersymmetry for Francesco Iachello's class on Group Theory, Lie Algebras, and their applications to physics. Many of the examples are taken from the material he provided me (c.f. the references section).(Fall 2015) [PDF]
Lectures and Notes
Graduate School:
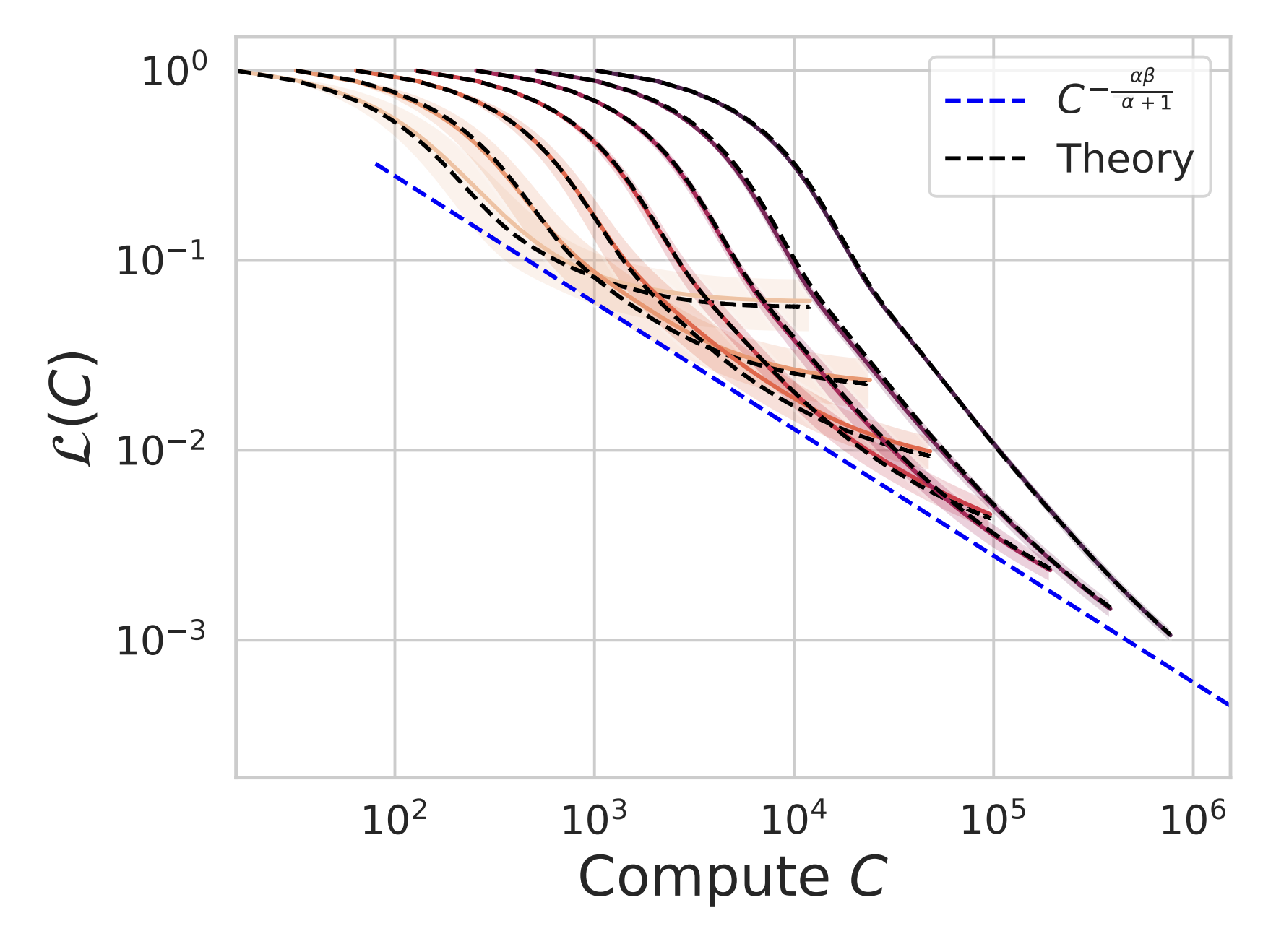
Simple Derivation of Neural Scaling Laws
Many of our papers [1] [2] [3] [4] focus on studying scaling laws in linear models. In order to cover all possible cases that arise, we must rely on techniques such as random matrix theory (RMT) or dynamical mean field theory (DMFT). Many other papers proceed similarly. This poses a barrier to entry, as theorists unfortunately tend to do. For practitioners, almost none of this is necessary to derive the scaling law exponents of interest in the regimes of relevance. One can derive the key scaling law in under 2 pages of basic math. I thank John Schulman for encouraging me to write and post this.(2025) [Note]
Notes on Statistical Mechanics and Learning
Various notes and solutions for textbooks I've read since 2021 to supplement my research. The topics range from statistical mechanics to neuroscience to deep learning theory and application.(2021-2023) [Bouchaud & Potters: Random Matrix Theory] [MacKay: Information Theory, Inference, and Learning Algorithms Part 0, Part 1, Part 2] [HST: Elements of Statistical Learning] [Engel and Van Den Broeck: Statistical Mechanics of Learning] [Kardar: Statistical Physics of Fields] [Mezard and Montanari: Information, Physics, and Computation Chapter 1, Chapter 4, Chapter 5, Chapter 8]
Solutions to "String Theory in a Nutshell"
In early graduate school, while still studying string theory, I wanted to get as much reading out of the way as possible. Alongside several books on quantum field theory, I did a cover-to-cover reading of E Kiritsis' "String Theory in a Nutshell" and tried to solve all problems. This is the write up for. Most problems are done, save for various topics in compactification and running of effective couplings, as well as the new edition's great chapter on applied holography. Perhaps I will one day finish these remaining problems. If you find errors and want me to make corrections, please do reach out over email. Also, if you have solutions to problems I haven't done, please also reach out. I'd love to add them in, of course crediting you.(2019-2020) [PDF]
Aspects of Open String Field Theory
Final project and presentation for Prof. Xi Yin's second semester course on string theory. Here I discuss string field theory, a "second quantized" formalism for dealing with off-shell processes in string theory. This is more involved than the commonly taught "first quantized" on-shell treatment of strings and superstrings. At least for open strings, there is a remarkably simple formulation in terms of Witten's "cubic" open string field theory (OSFT). In this final paper I give an exposition to this theory, and detail how the standard formalism can be used to recover the Veneziano amplitude, following Giddings. Then, I review Sen's remarkable paper demonstrating how the simple technique of level-truncation in OSFT can "see" the infamous bosonic string tachyon's potential and equate its minimum with the condensation of the D-brane.(Spring 2020) [PDF]
The Kondo Effect, Conformal Field Theory, and Quantum Dots
Final project and presentation for Prof. Ashvin Vishwanath's course on topics in quantum matter. Ken Wilson won the Nobel Prize in 1982 for applying his renormalization group (RG) technique to understand the low-temperature "strongly-interacting" regime of a the Kondo effect in a metal with magnetic impurity. From the modern perspective of studying field theory as a flow from one RG fixed point to another, we study a simple 1+1D version of the Kondo effect, and show how both the noninteracting and strongly-coupled fixed points can be understood in terms of WZW conformal field theories. We use this as a jumping-off point to think about how this formalism could shed new light into recent developments in understanding the Kondo effect in quantum dots.(Fall 2018) [PDF]
Holographic Duality and Applications
My set of handwritten notes for Prof. Hong Liu's Lectures on (MIT course 8.871) on the AdS/CFT correspondence. We begin with a motivation for holography from the thermodynamics of black holes demonstrating that their entropy must be proportional to horizon area. Then, after introducing the machinery from matrix field theory and string theory, we show how the large-N limit of matrix QFTs can be recast into an equivalent string theory-as in Maldacena's seminal paper. From here, we introduce the relevant concepts on both sides of the duality: anti-de Sitter space and conformal field theory, and apply this to understand phenomena such as quark confinement and entanglement entropy.(Fall 2018) [PDF] [Chapter 1: Black Holes and the Holographic Principle] [Chapter 2: Matrices and Strings] [Chapter 3: Holographic Duality]
Undergrad:
The Path Integral, Wilson Lines, and Disorder Operators
My lectures for Prof. Philsang Yoo's second-semester graduate seminar on the Langlands program. I define the ideas of quantum field theory for an audience of mathematicians. From here, I define the Wilson and `t Hooft line defect operators and elaborate on their relationship to the geometric Satake symmetries acting on both sides of the Langlands correspondence.(Spring 2018) [Lecture 1] [Lecture 2]
3D Monopoles and the Equations of Bogomolny and Nahm
My final presentation for Prof. Philsang Yoo's first graduate seminar on the ideas of the geometric Langlands program. This is introductory paper introduces the ideas of gauge theory for a mathematical audience, and then uses those ideas to define SU(n) monopoles in 3D in terms of translation invariant solutions to the anti-self-dual instanton equations in 4D (see prior lecture notes on instantons and the ADHM construction). This study of magnetic monopoles on 3D space serves to motivate the ideas behind the Nahm Transform, which will be explored in greater depth next semester for my senior thesis.(Fall 2017) [PDF]
Course Notes: Geometric Langlands and Derived Algebraic Geometry
My set of handwritten course notes for the lecture series of Prof. Philsang Yoo's graduate seminar course on the Geometric Langlands program, viewed through the lens of Derived Algebraic Geometry.(Spring, Fall 2017) [Full Notes] [Part 1: Categorical Harmonic Analysis] [Part 2: Moduli Space of Bundles] [Part 3: Geometric Satake] [Part 4: Geometric Representation Theory] [Part 5: Intro to Derived Algebraic Geometry] [Part 6: Back to Basics] [Part 7: Singular Support] [Part 8: Revisiting D(Bun_G)] [Part 9: How to study D(Bun_G)] [Part 10: Factorization Structures] [Part 11: Fundamental Local Equivalence]
3D Conformal Field Theory and the Ising Model
A set of lectures given both as a final presentation for my research in CFT over the spring of 2017, as well as a related talk given in the Fall as part of the Yale graduate seminar in representation theory, as an attempt to introduce the ideas of higher-dimensional CFT to a more mathematical audience with some background in the ideas of the Virasoro algebra for the 2D case.(Spring, Fall 2017) [Spring Talk] [Fall Talk]
2D Conformal Field Theory and the Ising Model
These lecture notes are from the final presentation given in Professor David Poland's graduate seminar in conformal field theory and its applications. The notes are based on the results from a paper by Belavin, Polyakov, and Zamolodchikov on the applications of 2D conformal field to various critical systems.(Fall 2016) [PDF]
Talks on the ADHM Construction, Hilbert Schemes, and the Heisenberg Algebra
The hardest, most rewarding math class I ever took during my time at Yale was Igor Frenkel's graduate representation theory seminar. I prepared a series of three one-hour talks, discussing how the ADHM construction gives rise to a moduli space of solutions that can be compactified and resolved. In particular, although U(1) instantons do not physically exist in a strict sense, the resolved compactification of the moduli space of U(1) instantons is nonempty, and in fact corresponds exactly to the Hilbert scheme of points on the complex affine plane. I discussed their homology rings and show that the algebraic structure is in fact intimately related to the Heisenberg algebra. This geometric realization is studied, in broad terms, by recognizing Hopf algebra structure both in the Heisenberg algebra and in the homology rings of the Hilbert schemes.(Fall 2016) [Review notes on Fiber Bundles] [Talk 1] [Talk 2]
Mentoring

Brian Zhang - RSI
I mentored Brian over the summer of 2024 as part of the Research Science Institute (RSI) program at MIT. I worked with him through a directed reading course in the modern theory of deep learning, focusing on the ideas of the neural tangent kernel and maximal update parameterization. Brian performed a sweep over a highly important yet understudied hyperparamter known as the "richness" of a deep neural network. This parameter interpolates between the network behaving as a linear model and the network learning features. He absorbed a wealth of theoretical information and leveraged it to empirically probe the weight structure changes of deep netorks as the richness parameter is varied. These preliminary studies have the potential to open the black box of neural networks to simpler interpretation. His final report was among five selected as distinguished written papers. Brian is now an undergrad at MIT 🎉(Summer 2024) [Final Paper]
Laia Planas - RSI
I mentored Laia over the summer of 2020 as part of the Research Science Institute (RSI) program at MIT. This was the first remote RSI, due to the COVID19 pandemic. I worked with her through a directed reading course in undergraduate quantum mechanics and quantum chemistry. This resulted in her completing a project that made use of graph theoretical methods to extract quantum-mechanical properties of carbon fullerene isomers. Laia is now an undergrad at the University of Barcelona 🎉(Summer 2020) [Final Paper]

Dylan Raphael - RSI
I mentored Dylan over the summer of 2019, as part of the Research Science Institute (RSI) program at MIT. I worked him through a directed reading course in undergraduate quantum mechanics and multilinear algebra, culminating in the introduction of tensor networks as a tool to understand interacting, many-body quantum systems. He developed a computational approach in the Julia programming language to study the phase transition of the tricritical quantum Ising model. Dylan is now an undergrad at MIT 🎉(Summer 2019) [Final Presentation]

Perimeter Institute ISSYP Mentorship
Lecture that I gave to the high school students participating in the Perimeter Institute's International Summer School for Young Physicists (ISSYP). Introduction of manifolds and vector fields to students with calculus background. Covered linear algebra topics such as direct sums and tensor products of vector spaces and co/contravariance. The end goal was to motivate the intuition behind the idea of a Lie Algebra/Lie Derivative in terms of flows along vector fields. The attached lecture sadly has no audio.(Summer 2016) [Lecture]
Books
Complex Analysis: In Dialogue
A book I wrote back in high school on complex analysis. It was initially a set of notes written as a result of self-study over the Summer of 2013. Gradually, it grew into a larger pedagogical work. The dialogue of the book is in the style of Johann Joseph Fux's work Gradus ad Parnassum, a formal conversation between teacher and student at length on a large subject. I swear I also had other hobbies when I was seventeen. You can buy it on Amazon here.(Fall 2013) [PDF]
Complex Analysis: Appendix of Color Plots
Accompanying color plots for students and readers to be able to visualize some of the complex functions mentioned in the above work. Color plots of complex functions are much more in-vogue now than they were a decade ago. I like to think that I played a small part. You can buy it on Amazon here.(Fall 2013) [PDF]